Shiny Appsで遊ぶシリーズ第2弾。第1弾は以下でした。
今回は,もっと単純に,名前の列を入力したらそれをランダムに並び替える,というだけです。発表順をランダムに決めるとか,議事録担当者をランダムに決めるとか,様々な場面でご利用いただけます。
https://yutamura.shinyapps.io/RandomOrder/
なにをゆう たむらゆう。
おしまい。

Shiny Appsで遊ぶシリーズ第2弾。第1弾は以下でした。
今回は,もっと単純に,名前の列を入力したらそれをランダムに並び替える,というだけです。発表順をランダムに決めるとか,議事録担当者をランダムに決めるとか,様々な場面でご利用いただけます。
https://yutamura.shinyapps.io/RandomOrder/
なにをゆう たむらゆう。
おしまい。

タイトルのとおりです。Rmarkdownをknitしたとき,ファイル名に日付を入れたい場合にどうするかというお話。自分用メモです。
ファイルの中身の日付は,YAMLヘッダーをいじることで対応可能です。
参考:自動で日付を変更する R markdown tips https://qiita.com/masato-terai/items/50afd48ad741aa8b7bb6
今回は,knitした際に生成されたWordやHTMLのファイルに日付をいれたいので,上記の話とはちょっと違います。
私が調べた感じだと,YAMLヘッダーの指定でファイル名に日付をいれるのは無理そうでした(ChatGPTはいけるって感じで説明してきましたが,そのやり方でやってもだめでした)。そこで,rmarkdown::render関数の中のoutput_fileの引数で明示的に日付を指定してあげるという方法をとります。下記のような感じです。
rmarkdown::render("Experiment1_Analysis.Rmd", output_file = paste0("Experiment1_", Sys.Date(), ".html"))指定するのは,
の3つのみです。2つ目のファイル名の部分に,”Sys.Date()”をいれて,paste0()でくっつけることで,最終的なファイルが上の例だと”Experiment1_2024-04-26.html”のようになります。knitボタンを使う代わりに上のコードを実行すると,ファイルが生成されます。
もちろん,YAMLヘッダー上で,”output:html”の指定は必要ですし,wordにするならwordにしないといけません。その部分の指定と,ファイル名の拡張子の指定が一致していないとおかしなことになると思います。
ちなみに,上のコード部分のRコードチャンクに”include=F, eval=F”等の指定をしてあげないと,最終的に出力されるファイルのなかにコードが残るので注意が必要です。
Rmarkdownからknitすると,基本的にファイル名=Rmarkdownのファイル名で,生成されたファイルのファイル名を自分で変えないと,基本的には上書きされてしまいます。よって,ログを残す意味でも日付を入れたいよねというのが動機でした。もちろん,同日内で何度もレンダリングすれば同じ日付で上書きされてしまいますので,その場合はSys.Date()ではなくSys.time()にする必要はあります。
以上,メモでした。
なにをゆう たむらゆう。
おしまい。
ずっと下書き状態だったんですが,もうこのままサクッと公開しようと思って公開します。授業の中で,今まで自分(教員)が学生の書いた英文(基本的には単文)にフィードバックしていたのですが,それを学生がChatGPTにフィードバックを求める課題にした,というお話です。
2回生向けの,Listening&Speakingの授業です(教養外国語のクラスで学部は理系)。クラスサイズは35名くらいで,教科書を使いつつ,半分くらいの時間はペアでのインタラクション・タスクをやっていました。そして,post-taskとして,ワークシートに「言いたかったけど言えなかったこと」という欄に自分がタスク中に言いたかったけどうまく言えなかったことを日本語と英語で書くということを学生には求めています。この部分は授業中に終わらなかったら宿題ね,という感じで,ワークシートは写真に撮ってPDFにして毎回LMS上で提出してもらっていました。このpost-task部分の英文をLMS上に提出されたPDFを見て,私からコメントが必要な場合はコメントを返す,というようにしていました。単文とはいえ,この言い方はどうなんだろう,と思うことは結構あって(もちろん自分の感覚が間違ってることもありました),それをChatGPTにやってもらおうと思ったという。最初は自分がChatGPTに学生の書いた英文を見てもらうようにしていたのですが,なにせLMS上でタイピングしているわけではないので,手書き文字をいちいち打ち直さないといけないと。どっちにしろめちゃくちゃ時間かかるじゃん,ということで,それなら学生がChatGPTで事前に添削してもらったものを教員がチェックするほうがいいかなということで,学生に使わせることにしました。
学生には,ChatGPTのアカウント作成方法などを書いた資料を配っていました(今はログインなしでも使えるのでこれは不要ですね)。ChatGPT3.5(無料版)だと,英文の添削と理由の説明をお願いしても,理由も英語で説明してくる場合があります(今はわからないです)。そういうときに,日本語で説明して,とやりとりをして日本語の説明を出してもらう,そういう部分も含めてスレッドを全部画像として提出するように学生にはお願いしていました。つまり,最初にどういう入力をして,どういう出力が返ってきたのかのやりとりを提出させる,ということです。こうすることで,一応ChatGPTが全部書く,ということを抑制しようという狙いがありました。
また,私はそこは直接的には狙っていなかったのですが,こういう方式をとることで,結構学生の学習になっている部分があるな,学習につながるやりとりができているな,と感じる部分もありました。一応こちらでテンプレのプロンプトは提示していますが,自分で考えて,「XXXXXXXXXXXXをYYYYYYYYYYと訳しました。あってますか」(Xには和文,Yには英文が入ります)と聞いてる学生もいました。その他にも,自分で色々気になったことを聞いてる様子がみられました(すべての学生からではないですが)。以下はその例です。
また,ただ添削するだけではなく,語彙や文法について,私が指示していなくてもChatGPTに聞いている様子もありました。さらに,次のようなことをChatGPTとやりとりしている学生もいました。
最初からうまくできるわけではないので,最初の何回かは明示的にうまく英文添削をしてもらえている例とうまくできていない例(例えば,自分で英文を作らずに日本語を英訳してもらうことをお願いしている,英文を添削してほしいというプロンプトなしで英文をChatGPTに投げるので,ChatGPTは普通にその英文に応答して会話をしているなど)を提示していました。そのうち,私が別に教えなくても学生自らが様々な方法でChatGPTとやりとりを繰り広げる様子が見られるようになったという感じです。
こうやって文法指導的な部分をChatGPTに外注していると,それまで授業の内外で自分が担っていた指導が必要なくなることになります。もちろん,ChatGPTの出力と学生の言いたいことをモニターして,うまく英文を作れていなかったら,あるいは文法解説が間違っていればこちらからフィードバックを出すことはあります。ただ,授業中に例えば学生の書いている英文に誤りを見つけたときに,迷うことが増えました。その場でフィードバックもできるのですが,結局あとでChatGPTに自分でフィードバックをもらいにいくことになるわけで,そこで誤りが見つかるほうが学生にとって良い経験になる可能性もあるのではないかと考えるようになったのです。
個人的な感覚ですけど,間違いを指摘される際にその場で,なんなら周りにそのことがもしかしたら聞かれているかもしれない,という状況でフィードバックをもらうよりは,自分の自学の時間で感情のないAIからフィードバックを受けるほうが精神的にいいのかなみたいな。
このあたりは,まだまだ試行錯誤という感じです。
ちなみに,学期末の授業評価アンケートで,このChatGPTに英文を添削してもらうという課題は意味がないからやめたほうがいいというコメントもありました。私から見ると有効活用している例が結構あったのでそれはいい英語学習になっているなと感じたのですが,私の意図が伝わっていない学習者にとってはこの課題自体を自分の英語学習に有用だという認識を得られなかったということになります。匿名のアンケートなので詳しくどういう印象だったかを聞くことはできなかったのですが,結構気にはなっています。
最近は研究でもどんどん生成AIの利用について様々な観点の研究が出てきていますね。実践するうえではそういう研究も参照しないとなーと思ったりはします(するだけ)。
なにをゆう たむらゆう
おしまい。
Querie.meでいただいた質問への回答シリーズです。
背景は以下のツイート御覧ください。
先程のtamさんの「高校教員から大学教員へのキャリアアップ」に関連するツイートを閲覧しました。
実際に大学教員と接していると高校や中学校の先生を下に見る教員が一定数いることも否めないのかなと思います。勿論、給与、専門性、働き方の面では下に見られても致し方ないこともあるのかと存じます。ですが、多くの現場の先生は目の前の生徒を思って本気で向き合っており、あえて大学教員と比べることによって中高の先生を下に見るような発言は非常に不快でした。
Tamさんの考えに本当に共感したため、送信させて頂きました。
あーそういう使い方もあるのか,とまずは思いました。匿名で共感を示すために質問する,ということですよね。リプライで共感しましたって言うのもはばかられるし…みたいなこともあるかもしれませんしね。私は特に自分がフォローしている人以外からのリプライやいいね・RP等が表示されない設定にしているので(これは精神衛生上の工夫です),これまでにもそうやってリプライもらっててスルーしていることがあるかもしれません(まあフォローしている人からのリプライにスルーすることもあるんですが)。そういうわけで,こうやって伝えていただければ確実に私にメッセージは届くので,ありがとうございます。
大学教員を講師として招いて研修とか「指導」をお願いすることもあるでしょうし,小中高の教員が大学教員を上に見ているからこそ,という側面ももしかするとあるのかもしれません。それが悪いという話ではなく,どちらの立場の人にもそういう構造が無意識に内面化されているのかもしれないなと思いました。私のツイートは感情的になってしまいましたが,下記の寺沢さんのツイートは冷静な指摘だと思いました。
ちなみにですが,質問者の方がおっしゃる「給与」の部分については,平均的には大学教員のほうが上かもしれませんが,個別のケースを見れば学校教員よりも給与の低い大学教員はいると思いますし,小中高->大学で「キャリアアップ」にならず給与が下がることもありうると思います。専門性についても,どちらも異なる専門性があるので比較はできませんよね。寺沢さんが書かれているように,「研究と実践」というのはどちらに優劣があるものでもないという理念が,教育に関わっている人になら当然あるはずですから。
働き方も大学教員はみな時間にゆとりがあってということもなく,大学教員でも仕事に忙殺されている人はいると思います。「大学教員になる方法」なんて煽られて大学教員になってみたけど実際には給料も下がるし仕事量も膨大でやりたい授業もできず,みたいな大学にしか就職できないっていう可能性だって全然あると思うんですよね。そうなっても,煽った人は何も責任取ってくれませんからねぇ。とはいえ,私も教員養成課程の学部生だったときには無邪気に大学教員にあこがれていて,『大学教授になる方法』という本をゼミの先生に紹介されて読んだ記憶もあります。
実務経験は大事な一側面ではあるでしょうし,学生によってはそれが説得力を持つものだと認識する側面というのはあるでしょう(最近そんなような話を聞いたばかり)。ただ,自分の経験も話すだけの授業じゃ大学の授業じゃないでしょう,っていうツッコミもありうると思いますし,大学で教えたいとか教員養成に携わりたいみたいな気持ちだけで「良い」大学教員になれるかというと,必ずしもそういうわけではないかなという気持ちもあります。英語の授業をする,ということについてはもちろんどこでやろうが一定程度共通する基盤の能力みたいなもあるでしょうけどね。
本題と関係ない話をつらつらとしてしまいましたけど,もうちょい自分の中でも考えを整理したいなと思う話題だっていうことがブログに書こうとして初めてわかりました。こういう機会を与えてくださった質問者の方に感謝しています。
なにをゆう たむらゆう。
おしまい。

以下の論文のレビューというと大げさですが,まあ読んで思ったことなどを書きます。
Hui, B., & Jia, R. (2024). Reflecting on the use of response times to index linguistic knowledge in SLA. Annual Review of Applied Linguistics, 1–11. doi:10.1017/S0267190524000047
X(旧Twitter)につぶやいたことの再構成という形で以下いきます。反応時間はReaction Timeなので,RTと省略して記述します。
正確さ見ずにRTだけ見たら本質を見誤るというのが1つ目の論点です。RTは,例えば判断課題のRT(語彙性判断課題,文法性判断課題等(Grammaticality Judgment Task; GJT))が使われることがよくありますが,その場合には,誤答(誤った判断)の試行は一般的には除外されます。よって,正答率が低いような文法知識を扱う際には誤答が多ければ除外される試行が多くなり,それだと分析で見たいものが見れなくなってしまうのではというのが著者の主張。
個人的には,そもそもRT使うのは正確さでは弁別できない事象を扱いたいからです。明示的知識・暗示的知識の枠組みでRTを使った課題が用いられているのも,正確さでは母語話者と変わらなくても,RTでは母語話者と差がある文法項目がある,というような前提があるわけです。よって,知識が獲得される初期段階や,そこからの熟達度による変化を対象にするのであれば,RTは使わずに正確性(正答率)を従属変数にするでしょう。もし見るなら正確さの「変化」とRTの「変化」ですね。この論文でもそういう話をしていますが,つまりは複数の観測点を設けて,正確さとRTの関係性を分析するということです。
ということで,それって当たり前体操では…?と思いました。初期段階で正確性を見るというのは,私が共同でやった下記の研究でも論じています。
Terai, M., Fukuta, J., & Tamura, Y. (2023). Learnability of L2 collocations and L1 influence on L2 collocational representations of Japanese learners of English. International Review of Applied Linguistics in Language Teaching. https://doi.org/10.1515/iral-2022-0234
RTを使う分析は,基本的には条件間におけるRTの差分の大きさに焦点があります。例えば,自己ペース読み課題(Self-paced reading task; 以下SPRT)で文法的な文を読んだときと非文法的な文を読んだときを比較し,非文法的な文でのRTが長い(読みが遅れる)ことを比較します。ポイントは,グループレベルで統計的に有意かどうか,というのが結果の解釈のポイントであることです。つまり,差分が小さい人もいれば,逆方向の人(文法的な文を読むときのほうが遅い人)もいるなかで,全体的な傾向としては非文法的な文の方のRTのほうが長いよね,ということをももって,その実験の参加者集団が何らかの文法的な知識を有していると推論するというわけです。
こういう前提はありながらも,実はSLA研究ではRTの差分が個人の知識や能力を反映しているように解釈している研究が存在しています。つまり,何らかのペーパーテスト的なもので測られる正答率と同じ扱いをしてしまっている,ということですね。例えば,何らかの文法性判断課題みたいなものをやったとします。すると,そのテストのスコアが高い人ほど,文法知識を有している(または文法知識が安定している)と解釈すると思います。この点は多くの研究で暗黙的に了解されていることでしょうし,母語話者がテストを受ければ,真面目にやっていないというような場合を除いて一貫して高い正答率が期待されるはずです。ところが,RTは前述のようにこうした個人の能力の反映とみなすことはできません。あくまでグループレベルで結果を解釈するのであって,非文法的な文を読んだときのRTの遅れが大きい人のほうがより文法知識を有している(または文法知識が安定している)と解釈することはできないはずなのです。繰り返しになりますが,母語話者を対象にしてSPRTをやっても,全員が非文法的な文の方に大きな遅れが見られるとは限りません。では,その時に母語話者の中にもその文法の知識がない人がいると考えるでしょうか。
それにもかかわらず,RTの差分をSEMに使ったり,あるいは独立変数や従属変数として扱って回帰分析をしてしまっている,これは問題だよね,ということです。この問題は個人的には超重要で5年以上前から思っていました(しSLRF2019でGodfroid先生にも質問しました)。
このセクションでは個別具体的な研究に対して批判的な言及をしているわけではありませんが,明示・暗示の測定具関係の研究でRTを用いた課題を構造方程式モデリング(SEM)に入れているような研究にはこの2つ目の論点の問題点がつきまといます。
あえて個別に名前や研究をここで挙げたりはしませんが,論文で引用されている研究の中にこの批判が当てはまる研究がいくつもあります。こういう大事な指摘を論文として国際誌に載せる力は私には残念ながらなかったので,こういう論調が出てきたことはいいことだと思いました。
RTの差分を使ってる研究ってどんなのがあるだろうと思われた方は,レビュー的なものが同じ第一著者の次の論文の中にあるのでこれを読まれるといいかと思います。
Hui, B., & Wu, Z. (2024). Estimating reliability for response-time difference measures: Toward a standardized, model-based approach. Studies in Second Language Acquisition, 46(1), 227–250. doi:10.1017/S027226312300027X
上記論文ではRT差分の利用について概念的な問題点を指摘しているというよりは,RT指標そのものの信頼性が低いという問題に焦点をあてているので,差分を使うことのぜひについてはそこまで論じられていませんが(福田先生とやりとりしている中で論文読み直してこのことに気づいたのでgracias)。
これが最後の論点です。SPRTやGJTには様々なプロセスが入ってるので、RTはピュアに知識を反映してると言えないのではないか,という話です。これ,まあそれはそうというか,それはわかったうえでやっていますけどね,というのが正直な感想です。他の要因が極力入りこまないように,条件間での刺激文の違いをできるだけ最小限に抑える工夫がされます。文法構造によってはそれができない場合もあるわけですが,その場合でも単語の長さを揃える,文法構造を揃える,というように実験前の統制が肝になるわけです。それでも単語の長さが違ってしまう場合などは,単語長(文字数で操作化されることが多いです)を回帰分析に入れて残差読み時間(Residual RT)を計算してそれを従属変数にしたり,あるいは単語長を共変量(covariate)として回帰モデルに組み込んだりします。よって,RTを盲目的に何かを表すものとしているのではなく,一応妥当な推論たりうるように実験上の工夫は施されていると思っています。
最後に次の引用の一節で述べられているとおり,「それが何を反映しているのか」,というのは別にRTに限らずあらゆる課題・テスト・測定具についてまわる問題でしょう。
These are perhaps not problems unique to RT research. The key message here is that to ensure validity of their measures (i.e., to make accurate interpretations of their results), SLA researchers should be mindful of the psychological processes involved in completing the tasks. While no measure is a pure measure of anything, knowing what is or can be underpinning a numerical result that we interpret is of paramount importance.
そんなこと言われなくても当たり前のことでしょうと思っている人がほとんどだと私自身は思っていますが,もしそうじゃないとしたらこの基本が頭になくてSLA研究やってるのやばすぎでしょと思ってしまいました。
個人的には1つ目と3つ目の論点は別に対して重要じゃないというか当たり前だよな〜って話でした。ただ,2つ目の論点はとても重要なので,ここだけに焦点をあてたconceptual review articleみたいなのだったらもっとよかったのにと思いました。論文を読んでブログ書いたのめちゃくちゃ久しぶりかもしれない。
なにをゆう
たむらゆう。
おしまい。

Querie.meでいただいた質問シリーズ。今回は,質問というより相談という感じですね。
4月から高校の教員になりました。もう辞めたくなるくらい業務量が多いです。自分自身の求める授業が校務分掌、クラブ活動、事務作業によってできていないです。もう辞めたいです。。。
まずは,4月から教員になることができたこと,おめでとうございます。「自分自身の求める授業」をお持ちだというところから,きっと教員になりたいと思ってなられたのだろうと推察します。最初は何もかもが初めてのことだらけなので,力の入れどころ,抜きどころ,もわからないのでアップアップになっちゃいますよね。
理想を追い求めることは重要だとは思いますが,持続可能性の方がもっと大事だと私は思っています。授業準備の時間が少ないということはそれはそれで学校教員の労働問題として大事なことではあります。そうではあっても授業以外の仕事も教員の仕事ではありますよね。授業以外の時間を効率化して授業準備にあてる時間を最大化することを考えると同時に,自分のQOLを維持しながらどういった授業が可能だろうかと考えることも大事になってくるのではないでしょうか。
自分をすり減らして数年間だけ理想の授業をやってやめてしまうよりも,自分の環境の中でできることを退職まで数十年続けるほうが,結果的にはより多くの生徒にポジティブなインパクトを与えることができると思います(もちろん,自分の授業が必ずポジティブなインパクトを与えるとは限らないわけですけど)。
質問者の方がどのような環境で働かれているのか等はわからないので具体的なことをアドバイスしたりはできませんが,目の前の生徒に向きあうことだけはやめないとか,何かこれだけは…という部分を自分の中で決めてみてはいかがでしょうか。授業でも,例えば何か一つここだけはこだわってやろう,と決めてみるとか。全部が全部完璧に,というのはなかなか難しいですし,仮に他の業務に忙殺されていなかったとしても,理想の授業ができるとも限りません。また,理想の授業というのも経験を重ねるうちに変化していくものだと思いますし。
自分に課すハードルが高すぎることが自分を苦しめてしまうということもあると思うので,それを下げてあげることで楽になる部分もきっとあります。それは自分を甘やかすこととは違うことです。これは個人によって考え方も違ってくるのでそれが正しいとかではなく私はこうしているっていうことなんですが,先のこととか大きいこととか,そういうのではなく,目の前の,小さなことをクリアしていくことを意識してみてはいかがでしょうか。「理想の授業」がどんなものかはわからないですけど,きっといろんなことがその中には詰まっていると思います。それを一旦バラバラにしてあげて,その小さなことを意識してみるというんでしょうかね。そういうのを続けていく中で,自分のパフォーマンスもあがっていくし,自分自身も成長できると考えています。
そんな要素還元主義的な考えで授業が成り立つわけないと思っていらっしゃるとしたら,うーんまあそういうこともあるだろうけどね〜って感じなんですけど。仮に真の現実が要素還元できないような複雑なものであったとしても,人間が理解して,そして生きやすいように要素に分けてあげることは全然アリだと私は思っています。
これは私自身も超絶苦手なことなので,誰かに言えるようなことでもないのですけどね。力を抜いて周りにも頼りながらやってみてはどうでしょうか。学校は組織ですから,授業も,校務分掌も,クラブ活動も,事務作業も,周りとつながりながらやっていくとバランスが取れるんじゃないでしょうか。それができたらわざわざ匿名で私のところに質問を送ったりしないとは思いますけど。同じ学校の中で悩みを共有できる人がいなかったとしても,一歩外に出れば,それこそSNSでもいいですし,学会とか研究会みたいなものでもいいですし,学校の外に出ればいろんなところで自分を支えてくれる小さなコミュニティに出会うことができると思います。その一つの手段として私に質問を送っていただけたのなら,それはとてもありがたいことです。もしまた何かあったら質問していただければと思います。
質問者の方と同じようなことを感じている人も他にもいるかもしれないなと思うので,そういう人たちにも届いてほしいなと思います。
なにをゆう
たむらゆう。
おしまい。

Prolificというクラウドソーシングサービスを使って参加者を集めて,ウェブ上で実験に参加してもらう,ということを何回かやりました。右も左もわからずでしたが,なんとなくこういうところに気をつけたほうがいいかな,とか,こういうのが便利,みたいなのを使っているうちに気づいたところがあるのでそのメモです。オンラインでデータ収集をすることに興味がある方にも参考になれば。
以上が基本的な流れです。個人的には,「3. 参加者グループの設定をする」は「2. 実験(Study)を作る」とは別で行うのが良いと思っています。2のページ内でも参加者のスクリーニングの設定はできるのですが,それは保存ができません。よって,前にデータを取ったときと同じ設定でデータを取りたいな,と思っても,またそのページを見に行って,設定をメモして,それと同じ設定をする,ということをしなくてはいけなくなります。例えばですが,「UK在住英語母語話者」みたいな特定の集団に対して募集をかける,ということが複数予想される場合には,先にその自分が想定する参加者集団の設定を”Participants”のページで作っておけば,何度も使いまわしができます(もちろん,設定の一部を変更することはあとからできますし,グループは複数作れます)。下記画像は,私が最近英語母語話者向けのデータ収集で使った設定です。

pre-postとか,あるいは複数の実験のデータを統合したりなどといった実験デザイン上の制約で,同じ参加者に複数回の実験に参加してもらいたいという場合がありますよね(3つの実験をやってもらいたいけど,一度に参加してもらうには時間が長すぎるので複数回に分けたい場合なども含みます)。普通にデータ収集をしたら,その設定に当てはまる人の中で早い者順で埋まっていくくので,同じ人が参加してくれるとは限りません。そういうときには,2つの方法があると紹介されています。
How do I set up a longitudinal / multi-part study?
How can I invite specific participants to my study?
1つ目が,参加者のスクリーニングで,過去に特定の実験に参加して,”approveされた人のみ”を含む設定にすることです。2つ目は,時間的に先行する実験に参加した人のIDリストを使って,カスタムでそのIDリストの人たちのみが次の実験に参加できるようにするものです(”custom allowlist”)。どちらも2つ目のリンク先で説明されているのでそちらを読んでみてください。私は2つ目の方法を用いました。理由はいくつかありますが,時間的な制約で1つ目の実験が終了する前に2つ目の実験を公開したかったというのがあります。このようにすると,2つ目の実験を公開したあとに1つ目の実験に参加して終了した人は,2つ目の実験公開時点では参加者プールの中には含まれません。しかし,”custom allowlist”は,あとからそのリストにIDを追加していくことができるのです。よって,例えばですが90/100人くらいが終わった時点で2つ目の実験をその90人をリストに入れた状態で公開し,残りの10人はあとからIDを追加する,ということができます。
この方法は,とくに2回目->3回目以降で力を発揮します。というのも,1回目のデータ収集は,母語話者にしろ第二言語学習者にしろ,設定した集団があまりにも特殊すぎなければ,かなりの人数が対象になるので,割とすんなりと枠が埋まります。一方で,2回目から3回目は,1回目に参加した人が対象になります。その人達が必ず2回目,3回目とすべての実験に参加してくれるとは限りませんので,枠が埋まるスピードがかなり遅いです。時間的に先行する実験枠がすべて埋まってから次の実験を公開する,とやるよりも,ある程度の人数が参加してくれたら次を公開する,というように流していくのがベターだと思いました。
前節のパターンと逆で,同じような実験だから過去に自分の実験に参加したことがある人には募集がいかないようにしたいケースです。これは,前節とまったく逆のパターンをすればよいです。スクリーニング設定で”Participation on Prolific”というカテゴリがあり,そこに”Exclude participants from other studies”というサブカテゴリがあるので,それでどの実験に参加している人を除外するかを選択することができます。もちろん,custom allowlistと同じ要領で,”custom blocklist”というのもあるので,任意のIDを参加不可能にすることもできます。
ちゃんとやっているかを確認する手段を用意して,それに基づいてリジェクトしないといけません。なんかちゃんとやってなさそう,くらいだと根拠としては弱いです。Prolificでは,下記のような基準を出しています。
詳しくはこちら->https://researcher-help.prolific.com/hc/en-gb/articles/360009223553-Prolific-s-Attention-and-Comprehension-Check-Policy#h_01FS4DYYVP24GDYK7D0A8PSYF8
- They should check whether a participant has paid attention to the question, not so much to the instructions above it
- Questions must not assume prior knowledge
- Participants must be explicitly instructed to complete a task in a certain way (e.g. ‘click ‘Strongly disagree’ for this question’), rather than leaving room for mis-interpretation (e.g. ‘Prolific is a clothing brand. Do you agree?’)
- They must be easy to read (i.e., should not use small font, or have reduced visibility)
- They cannot rely on memory recall
- If your study is 5 minutes or longer, then participants must fail at least two checks to be rejected, any shorter studies can use a single failed check to reject
上の引用している基準が掲載されているページには,どういうのがいいIMC(Instructional Manipulation Checks)の例でどういうのが良くない例なのか,というのも載ってます。
個人的なポイントは一番目と最後のブレットポイントかなと思います。どのように質問に答えるのか,という指示よりも質問それ自体に注意を払っているのかをチェックすることというのが一番目ですね。最後のやつは,5分以上かかるなら2つIMCを用意しないと,リジェクトできない(参加者に報酬を払うことを拒否できない)ということになります。
すべてポンド換算で,小数点第二位まで指定できます(e.g., 4.51, 6.89)。だいたいどのくらいの時間がかかるかを見積もって,その時間に対していくら,という設定をします。例えば実験が30分だとすると,
みたいな感じになっているようです。これは参加者に支払う金額です。これ以外にも,Service feeが約3割かかります。例えば,50人に対して£6の報酬を設定すると,報酬が£300,Service feeが£100です。
普通のアンケート調査のようなものであれば,Googleフォーム等のURLを使えば問題ないでしょう。私はGorilla Experiment Builderを使ったのと,jsPsychで作ったプログラムをGoogleのFirebaseと連携させてデータ収集をしました。前者のGorillaはGUIが基本で,それでも結構複雑な実験を作ることができますし,実験プログラムを作ってそのデータを保存するところもすべてシステム上でできるので,安心感もありますね。もちろん,利用するためにお金はかかるのですが(こちらの料金設定等はちょっと自分では払ってないのでわからないです)。
後者のjsPsychとFirebaseの連携は,実質無料です。Firebaseで有料枠にいくのはかなりの量のデータを短期間に動かさないといけないと思うので,私が利用する分には特に有料にしないといけないということにはなりませんでした。使い方等はウェブ上に日本語で書かれたものも含めてかなりリソースがあるので,それを参考にしました。ただ,ChatGPTやCopilotに手伝ってもらえるとはいえ自分でコードを書いたり,データベースの設定をしたり,と自分でやる部分がかなり多いので,少しハードルは高いかもしれません。私も結局数年間ずっと取り組もうと思って挫折をしまくり,この春休みで鬼のように取り組んでようやく自分がやりたいと思う実験(プライミング付き語彙性判断課題,自己ペース読み課題,語数判断課題)についてはプログラムを書いて保存してという基本的なところはできるようになりました。もちろん,細かいところは改善の余地があるのですが,まあ実際にプログラムが動いて,そのデータが保存される,という根本的なところはなんとか,という感じですね。たぶんいつかウェブにソース公開すると思います。
データベースに保存がうまくできているのかとか,プログラムが上手く動いているのかといった確認が必要なのは,GorillaでもjsPsych×Firebaseのどちらのやり方でも一緒ですね。いずれの方法でも
という2つによって,実験に参加したことが確認されるようになっています。
この記事では,Prolificで参加者を集めてオンラインでデータ収集をする,という話について書きました。後半の実験を行う2つのプラットフォームの話やProlificを実際に使ってみてのあれこれのエピソードなんかはまた別の記事にしたいと思います。
もし,これってどうなんだろう?と気になったことがあれば,下記のリンク先から質問していただければ,私が答えられることであればお答えします。
https://querie.me/user/tam07pb915
なにをゆう たむらゆう。
おしまい。

Querie.meでいただいた質問シリーズ。
文法習得にフォーカスするSLAの研究で、自分のリサーチクエスチョンに至るには、先行研究を読んでまとめることを繰り返して、そのまとめたものから、リサーチ・ギャップを見つけるというかたちで進めればよいのでしょうか。 4月から進学する学生なのですが、「これまでに何がわかっていて、何が課題なのか」という部分をまとめるのがすごく苦手な気がしていて、お尋ねする次第です。アドバイスをよろしくお願いします。
おっしゃられている方法(「先行研究を読んでまとめることを繰り返して,そのまとめたものから,リサーチ・ギャップを見つける」)は,文法習得とかSLAとか関係なく大事なことなのかなと思います。リサーチ・ギャップを見つけてそれを埋めるより,既存のリサーチの前提を問い直す研究の方が本当は大事なことなんですけどね(参照:『面白くて刺激的な論文のためのリサーチ・クエスチョンの作り方と育て方』)。「進学」が修士課程への進学だとしたら,そういう研究をするのはかなりハードルが高いので,個人的には目指さなくてもいいと思います(もしできるのならそれは素晴らしいこと)。もし博士課程に進学されるのなら,単なるギャップを埋める研究ではなくもっと野心的な研究に挑戦してみてください。
あとは,個々の論文だけ読んでいても、いわゆるbig pictureというか,それがより大きな領域・分野のどういうところに貢献するのか,みたいなことがわからないままになってしまうと思います。だからこそ,いわゆる教科書的な本は何冊でも読んだら読んだだけ得るものがあると私は思っています。
「これまでに何がわかっていて,何が課題なのか」というのは,たいていの場合論文のイントロに書いてあると思います(私は少なくともそういう意識でイントロを書くようにしています)。イントロがなく,いきなりliterature reviewから入る論文でも,本研究に入る前のところで,研究の意義とか目的みたいなものを書いているパラグラフがあると思います。それが,「これまでに何がわかっていて,何が課題なのか」に関係していますよね。
また,「何が課題なのか」については,論文の最後の方,”future directions”てきなのが書いてあるパラグラフがあると思います。あるいは,limitationsの部分に,今回の研究の限界が書かれていると思います。その限界というのは,今後の課題につながる部分でもあるはずですよね。例えば,今回の結果Xの効果が見られたが,実際にはこういう実験をしてみないとYの影響がある可能性もある,というような話があれば,「こういう実験」というのが次にその領域でやるべきこと,でしょう。そういうののなかで,自分がやってみたい,と思うことがリサーチクエスチョンになるんじゃないでしょうか。
私の場合は,修士論文も博士論文も,「なんかこれおかしくない?」みたいなのが動機というかスタート地点でした。修士論文のときは,読解中に線引いたらそれすなわち”noticing”みたいになってるけど線引いたときに何考えてたかわからなくない? -> 刺激再生法でインタビューしてみよう,みたいな感じでした。博士論文は,複数形形態素の習得ではよく数の一致現象が取り上げられるけど,数の一致は処理が複雑だから,それができない=複数形形態素の習得ができないとかそういうことじゃないんじゃないの? -> もっとダイレクトに複数形形態素とその意味のマッピングを「習得」と定義して,そのマッピングを調べる実験をやってみよう,みたいな感じでした(参照:Tamura, 2023)。
所属する研究科や指導教員の先生のやり方等もあると思うので,そういうのを入ってから学びながら,という側面も結構あると思います。こうやってリサーチ・クエスチョンを立てなさい,というような具体的な指導があるかもしれませんしね。上で書いたことはあくまで「私はこう考えている」ということなので,大学院に入ったら実際には私が書いたこととは全然違ったみたいなこともあるかもしれません。そこはご理解ください。
最後に,ゼミや授業その他でいろんな論文や研究について色々ディスカッションする中で研究のアイデアが生まれることもあると思います。私が大学院(博士課程)のときは,喫煙所でいくつものアイデアが生まれたような記憶があります。
今でもすごく自分の記憶に残っているのは次の研究です。
2017に出た論文ですが,2016年にやった研究だと思います。草薙さんや福田さんという私がすごくお世話になった先輩が名大からいなくなって,自分が引っ張る立場になりました。そんなとき,後輩の西村くんと帰り道に理系の方の喫煙所に寄って,研究の話をしました。彼は当時から統語的複雑さというものに興味を持っていました。そこで,統語的複雑さの指標(節の数とか従属節の割合とか)があがったさがったとか,そういうのよりも,「どうやって統語的に複雑な文を書くのか」に注目したらどうかという話になりました。普通にライティングをさせてもそこまで複雑な文は出てきませんし,明示的に複雑な文を書いてください,と指示しても,その指示の中に複雑な文の具体例を出さなければならず,実験としては成り立ちません。そこで,6コマ漫画の描写課題で書ける文の数を制限させるという条件を課すことで,限られた文の中に多くの情報を詰め込まなければいけない状況を生み出しました。「一番複雑な文を書く大会」というプロジェクト名で,もう一人の後輩(原くん)も誘って3人で研究をしました。中部地区英語教育学会で発表して,全国英語教育学会紀要に投稿し,無事採択されたというわけです(引用されたことないんですけどね….)。
こんな風に,誰かと話している中からアイデアが生まれて,それが研究になる,ということもあると思います。もちろん,こうやって形になった研究なんてほんの一部で,考えていった結果としてこれじゃ研究にならないな,といわゆるボツになったものも数え切れないくらいあると思います。進学される大学院にフルタイムの学生がたくさんいて,毎日毎日研究の議論をたくさんする,というような環境ではないかもしれません。そんなときは,研究会や読書会に参加したり,学会に参加したりしてみると,そういう議論の機会も得られると思います。
4月からの大学院生活,楽しんでくださいね。応援しています。
質問したい方はどうぞ。
https://querie.me/user/tam07pb915
なにをゆう たむらゆう。
おしまい。

私って,授業でグループ・ディスカッションとかよくすることがあるんです。そのときに,ランダムにグループ分けをしています(そうしないほうがいいときもあるでしょうけど)。そこで,いつもは下記のサイトにあるRコードを使って,その場でRを回しています。
ただ,Rを開いて,コードと名前リストをコピペして,っていうのがやや面倒なんですよね。それから,クラスの人数を把握して,何グループ作ったら何人のグループがいくつできるのかとか,そういうのを瞬時に頭の中で計算できた試しがありません。ぱっとその場で計算の得意な学生に聞くこともあるのですが,ややもたつきます。そこで,機械にやらせちゃおう,というお話。
ChatGPTに,こういうのを作りたい,と相談してコードを書いてもらい,修正したい部分が出てきたらその都度コードを書き換えてもらいながら1時間位で作りました。
https://yutamura.shinyapps.io/RandomGroup
名前リストをコピペして貼り付けて,グループ数を調整したらグループ分けがされます。
こだわりポイントはこんな感じで,今いる人数を計算して,何人のグループがいくつできるのかを提案してくれることです。
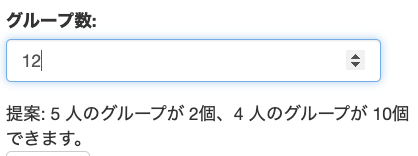
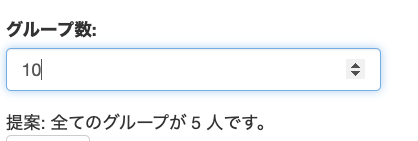
最初は,グループの数のあとに「つ」がついてたのですが,例えば,「5人のグループが10つできます」みたいな時が出てしまいます。数が二桁超えると「つ」はつかないですよね。もちろん,グループ数が多くなったら変えるみたいなロジックを追加することもできるっちゃできるわけですが,ちょっとめんどくさいなと思って(いや自分でコード書いてるわけじゃないんですけど),全部「個」にしました。「個」最強。ちょっと違和感あるにはありますけど。
100行まで名前リストを入力できるようにしているので,100人サイズのクラスまでは対応できるかなと思います。それより多くなったら2回に分けてもらう感じですかね。
インタラクティブな仕様にしたので,グループ数を変えていけば,その下の提案も変化して,自分で何人のグループがいくつにできるのかいくつか候補を見たうえでグループ分けができます(俺得)。
ChatGPTに,お試し用にコピペして使える名前リストを出してもらったので,このリストをコピペして実際にどんな感じか使ってみてください。
Alex Smith
Sam Johnson
Charlie Williams
Taylor Jones
Jordan Brown
Skyler Davis
Morgan Miller
Casey Wilson
Jamie Moore
Avery Taylor
Alex Smith
Sam Johnson
Charlie Williams
Taylor Jones
Jordan Brown
Skyler Davis
Morgan Miller
Casey Wilson
Jamie Moore
Avery Taylor
Alex Smith
Sam Johnson
Charlie Williams
Taylor Jones
Jordan Brown
Skyler Davis
Morgan Miller
Casey Wilson
Jamie Moore
Avery Taylor
Alex Smith
Sam Johnson
Charlie Williams
Taylor Jones
Jordan Brown
Skyler Davis
Morgan Miller
Casey Wilson
Jamie Moore
Avery Taylor
Alex Smith
Sam Johnson
Charlie Williams
Taylor Jones
Jordan Brown
Skyler Davis
Morgan Miller
Casey Wilson
Jamie Moore
Avery Taylor
※名前被ってたりして芸がない
いや,こんなことやってる場合じゃないんだ本当は…
なにをゆう たむらゆう
おしまい。
ある特定の学会誌の話をします。学会の中でどんな議論がされているのかは全く知りません。
学会誌って,学会員の成果を発表する場ですよね。たくさん投稿してもらって,その中から選ぶプロセスが多少あったとしても,1本しか載らないような学会誌に私は投稿しようとすら思いません。また,存在意義もわかりません。
そんな低い採択率突破したところで,語弊を恐れずに言えば「たかが」学会誌です。著者の知り合い以外に大して読まれもしないでしょうし,ごく少数の論文を除いては誰にも引用されない可能性だってありうるのではないでしょうか。
そうであるならば,それなりに通りやすい国際誌に出した方が,そもそも届けられる読者の数が段違いですし,国際誌に載った,という「箔」もつきます。そういう状況ならそっちに出すでしょう。そういうひっくり返しようのないヒエラルキーを認めたら学会誌として価値がなくなってしまうんでしょうか。私はそうは思いません。学会は発表してもらって,論文投稿してもらってなんぼでしょう。
「ヤバい」論文を載せたら学会誌の評価が下がるとか,学会の評判が悪くなる,とかそうした考えがあるのかもしれません。それが全くわからないわけではないし,何でもかんでも載せていいとは思いません。
ただ,論文の質が低かったらそれは著者の責任でしょうし,論文の評価は著者の評価に最も直結するのではないでしょうか。質の悪い論文があったら,いの一番に著者が批判にさらされるべきでしょう。そういう議論だって表立って行われれば健全な学術コミュニティのあるべき姿とも言えるはずです。
少なくとも今の段階では,多くの国際誌のように,インパクトファクターがついていて,どれだけ引用されるかといった指標で評価されたりランキングされたりするわけではないわけです。
自分自身が国際誌の査読をしてても,結果としてリジェクトになる率の方が多いです。そういう現実があっても,論文の質(研究の質)を引き上げる役目も査読のプロセスの中にはあるはずでしょうし,学会誌を出している学会にはそうした役割もあるはずです。
いい研究がどんなものか,という評価はある程度さまざまな観点があると思います。それ自体が悪いとはと思いません。でも,どちらかというと査読って,これはダメだよね、というのを弾いて(またはそこを修正してもらって)あとはどんどん載せればいいのではないでしょうか。もしも,これがいい研究なんだ,というのを対外的に示したいのであれば、その中から論文賞のようなものを選べばいいでしょう。
上で貼ったX(旧Twitter)で話題になった学会誌の査読委員や編集委員が論文書いていないとか論文指導していないってことはないような気もしますが(知らんけど),こういう意見もあります↓
今後,学会がしぼんでいって終いにはたたむ予定,というのなら,今の方針でも全く問題ないと思います。ただし,「若い人が減っている」みたいなことを嘆くようなら,やってることちゃんちゃらおかしいと思います。
昔の名残りなのか驕りなのかわかりませんけど,時代が変わっていることを認識して学会のあり方みたいなのも変えていかないと,ただでさえ存続が難しい学会が多いのに小規模学会はもっと厳しくなること間違いないと思います。
学会誌の査読って(というより査読システム全般って),そろそろ見直す時期に気ていると思います。こういう意見もあります↓
シンポジウム面白そうなんですけど,登壇者を誰にするか,っていうのは結構難しい問題だよな〜というのは具体的な企画をイメージして思いました。
なにをゆう たむらゆう。
おしまい。
